This post describes a pattern for implementing a continuous integration (CI) pipeline using Bazel. This pattern is my starting point whenever I set up a new Bazel-based project in CI, after which I add any project-specific pipeline customizations.
This pipeline is purely about the CI (build to release) stages of a pipeline. A full continuous delivery (CD) pipeline, which includes deployment, will be discussed in a later post.
Basic Pipeline Structure
The basic pattern for the CI pipeline looks as follows:

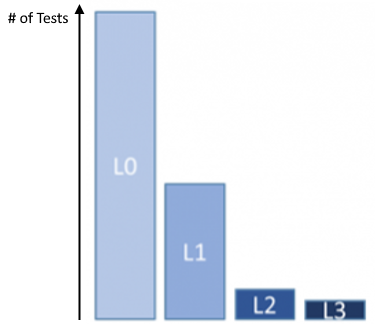
An "ideal" test case distribution
- Setup
- Perform any initial setup required in the pipeline, such as pre-execution validation, authenticating to Azure / AWS, etc.
- Compile
- Build all software in the project
- L0 Tests
- Build and run level 0 tests – quick-running, short-lived test cases that typically do not require network connectivity or external resources (a.k.a. unit tests)
- L1 Tests
- Build and run level 1 tests – medium-duration test cases that are slightly more time consuming and resource intensive
- L2 Tests
- Build and run level 2 tests – long-duration test cases that are even more time consuming and resource intensive
- Ln Tests
- Additional level of tests, where each level is even more time consuming and resource intensive. Insert as many levels as you deem necessary.
- Release
- Version and publish all tested artifacts to appropriate artifact repositories
The only particularly notable thing about this pipeline is that test cases are broken into broad stages. The idea is that earlier test stages execute more quickly, and we can avoid executing the more time consuming and resource intensive tests in later stages if the earlier stages failed. To avoid bikeshed arguments about test classification nomenclature (e.g. what belongs as a “unit test” vs. an “integration test” vs. a “system test”), test stages are given numbers with only broad guidance about what belongs in each stage. In short, don’t get too hung up about whether a particular test is L1, L2, or L3… just put it somewhere and move forward.
Setup Stage
The setup stage is where we perform any work necessary before we begin compiling and testing software using Bazel. Notable things I’ve put in this stage include:
- Reporting system details (e.g.
dpkg -l,uname -a,df -h) to help with troubleshooting build failures - Retrieving and initializing SSH keys
- Authenticating to cloud providers (e.g. Azure, AWS) or external services such as container repositories
- Creating a Bazel outputUserRoot directory if it does not already exist on an ephemeral drive so that Bazel can use the ephemeral drive for build outputs
- Removing any Bazel convenience symlinks if they exist, as these can sometimes break build tasks
- Finding any Bazel test cases that have not been associated with a test stage (see Ln Test Stage below)
Compile Stage
The compile stage is the most straightforward. In most cases it corresponds to nothing
more than executing bazel build //....
Additional considerations include:
- Will you perform a
bazel cleanbefore the build? (Not recommended in general, but in certain cases it is useful) - Will you be performing an optimized or debug build?
- Will you use a remote build cache to accelerate builds?
- Will this particular CI pipeline execution upload its results to the remote build cache?
- Will you use a tool like bazel-diff to only build what changed since the last CI successful pipeline execution?
Ln Test Stage
In each test stage, we instruct Bazel to find all test cases associated with the stage and to execute them.
I recommend using Bazel tags to
associate a test case with a test stage. For example, to mark a test case with the test stage L0,
add a tags = ["L0"] stanza to the test, as in:
sh_test(
name = "l0_test_case",
...,
tags = ["L0"],
)
With this done, all tests for the L0 stage can be executed using the command bazel test --test_tag_filters=L0 //....
Extending this to other test stages is straightforward.
An alternative to using tags to define tests is to create a Bazel test_suite() target and
invoke the test suite target directly.
In order to avoid the possibility that a developer defines Bazel test case without assocaiting it to a stage, I recommend adding a step to the Setup stage which looks for any tests that do not have a valid test tag, and failing the pipeline if any are found. Fortunately, Bazel’s query support makes this easy – here’s a simple script which does this:
#!/bin/bash
#
# find_untagged_tests.sh: Find all Bazel tests that do not have required tags
set -euo pipefail
# All tests must have either L0, L1, L2, or manual tag
UNTAGGED_TESTS=$(bazel query 'tests(//...) except attr(tags, L0, tests(//...) except attr(tags, L1, tests(//...) except attr(tags, L2, tests(//...)) except attr(tags, manual, tests(//...)')
if [ -n "${UNTAGGED_TESTS}" ]; then
echo "ERROR: Following Bazel tests are untagged; ${UNTAGGED_TESTS}" 1>&2
exit 1
fi
# Testing tags L0, L1, L2, and manual should be mutually exclusive.
BAD_L0_TESTS=$(bazel query 'attr(tags, L0, tests(//...)) intersect(tags, "L1|L2|manual", tests(//...))')
if [ -n "${BAD_L0_TESTS}" ]; then
echo "ERROR: Following Bazel tests are tagged with L0 and one of L1, L2, or manual: ${BAD_L0_TESTS}" 1>&2
exit 1
fi
BAD_L1_TESTS=$(bazel query 'attr(tags, L1, tests(//...)) intersect(tags, "L2|manual", tests(//...))')
if [ -n "${BAD_L1_TESTS}" ]; then
echo "ERROR: Following Bazel tests are tagged with L1 and one of L2 or manual: ${BAD_L1_TESTS}" 1>&2
exit 1
fi
BAD_L2_TESTS=$(bazel query 'attr(tags, L2, tests(//...)) intersect(tags, "manual", tests(//...))')
if [ -n "${BAD_L2_TESTS}" ]; then
echo "ERROR: Following Bazel tests are tagged with L2 and manual: ${BAD_L2_TESTS}" 1>&2
exit 1
fi
Additional test case considerations include:
- Will you test optimized or debug builds?
- Do you need to define additional, separate CI pipelines outside of the main which perform more intensive tests, such as a nightly test suite?
- Is the lack of test cases at a given level an expected or unexpected failure? (Bazel by default returns a non-zero
exit code if you try to execute
bazel testand no tests match the criteria) - How will you collect and report aggregate test results across all test stages?
- Do you collect code coverage statistics as part of your testing process?
- Will you use a tool like bazel-diff to only test what changed since the last CI successful pipeline execution?
Release Stage
In the release stage, we take the compiled and tested artifacts and upload them to the appropriate
Artifact repository. Indivdiual release tasks are almost always modelled as bazel run rules, often with names that
end in _push (e.g. container_push
from rules_docker).
Each individual CI release target is responsible for performing the tasks necessary in order to perform the release, including authenticating to the necessary services. The information in Practical Bazel: A Simpler Way to Wrap Run Targets may be useful here.
To allow CI to perform release by executing a single bazel run command, I recommend grouping all release
tasks into a single target using multirun:
# //:BUILD file at root of repository
multirun(
name = "ci_release",
commands = [
"//target1:ci_release",
"//target2:ci_release",
...
],
parallel = True,
)
Putting it All Together
With these tools and techniques in place, a starting Bazel CI pipeline looks as follows:
- Setup
find_untagged_tests.sh(see above)- Compile
bazel build //...- L0 Tests
bazel test --test_tag_filters=L0 //...- L1 Tests
bazel test --test_tag_filters=L1 //...- L2 Tests
bazel test --test_tag_filters=L2 //...- Ln Tests
bazel test --test_tag_filters=Ln //...- Release
bazel run //:ci_release