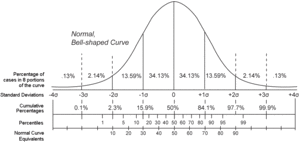
This is part 1/8 of my Calculating Percentiles on Streaming Data series.
Suppose that you are dealing with a system which processes one million requests per second, and you’d like to calculate the median percentile response time over the last 24 hours.
The naive approach would be to store every response time, sort them all, and then return the value in the middle. Unfortunately, this approach would require manipulating 1,000,000 * 60 * 60 * 24 = 86.4 billion values – almost certainly too many to fit into RAM, and thus rather unwieldy to work with. This begs the question “Is it possible to compute quantiles without storing every observation?”
Munro and Paterson [MP80] proved that a lower bound of $\Omega(n)$ space is required to exactly compute the median of $n$ values. However, if we’re allowed to compute an approximation, then there are a set of algorithms which can process the data in a single pass, and thus can be used without storing every observation. Notable algorithms with this property include:
- Manku, Rajagopalan, and Lindsay [MRL98] – single-pass, but an upper bound on $n$ must be known a priori; seems generally superseded by [GK01]
- Manku, Rajagopalan, and Lindsay [MRL99] – randomized algorithm
- Greenwald-Khanna [GK01] – single-pass, improves on the space bounds of [MRL98], and removes the requirement that $n$ is known in advance
- Gilbert, Kotidis, Muthukrishnan, and Strauss [GKMS02] – randomized algorithm, supports deletes as well as inserts
- Cormode and Muthukrishnan [CM04] – improves on the space bounds of [GKMS02]
- Cormode, Korn, Muthukrishnan, Divesh Srivastava [CKMS05] – improves [GK01] by better handling distributions with skew when finding targeted quantiles
- Tim Dunning’s T-Digest
The above list is intended to be representative, not exhaustive.
In this blog post series, I will explore various methods for calculating percentiles on streaming data.
References
- [CKMS05] G. Cormode, F. Korn, S. Muthukrishnan and D. Srivastava. Effective Computation of Biased Quantiles over Data Streams. In Proceedings of the 21st International Conference on Data Engineering, pages 20-31, 2005.
- [CM04] G. Cormode and S. Muthukrishnan. An improved data stream summary: The count-min sketch and its applications. Journal of Algorithms, 2004. in press.
- [GK01] M. Greenwald and S. Khanna. Space-efficient online computation of quantile summaries. In Proceedings of ACM SIGMOD, pages 58–66, 2001.
- [GKMS02] A. C. Gilbert, Y. Kotidis, S. Muthukrishnan, and M. Strauss. How to summarize the universe: Dynamic maintenance of quantiles. In Proceedings of 28th International Conference on Very Large Data Bases, pages 454–465, 2002.
- [MP80] J. I. Munro and M. S. Paterson. Selection and sorting with limited storage. Theoretical Computer Science, 12:315–323, 1980.
- [MRL98] G. S. Manku, S. Rajagopalan, and B. G. Lindsay. Approximate medians and other quantiles in one pass and with limited memory. In Proceedings of ACM SIGMOD, pages 426–435, 1998.
- [MRL99] G. S. Manku, S. Rajagopalan, and B. G. Lindsay. Random sampling techniques for space efficient online computation of order statistics of large datasets. In Proceedings of ACM SIGMOD, volume 28(2) of SIGMOD Record, pages 251–262, 1999.